My title
Chris Culy
AVML, 7 September 2012
My Three Perspectives
-
Language
-
Models
-
Tools
Mention Math Models as inspiration
Visualizations put ideas into our heads …
What questions come to mind?
What makes L/L data different?
-
Language is not mappable
-
Strings are special
-
Individual pieces of L/L data are meaningful
* Some L/L data that is not (strictly) textual at AVML:
Geographic information (e.g. typology, dialect mapping papers)
Audio/Video (as original data)
Sound information (waves, spectograms, intonation curves, etc)
Time duration in Speech/dialog info (e.g. pauses, overlaps, etc)
* Connection with original data at AVML: Text Variation Explorer
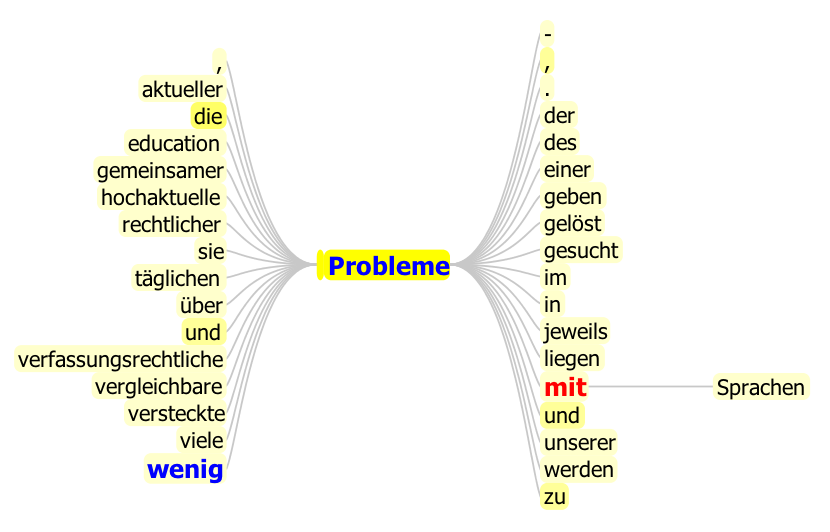
Strings are special
| Müdigkeit , | Darmproblemen | , Übergewicht |
| können das | Problem | nur teilweise |
| , gemeinsames | Problem | : den |
| Jahren das | Problem | auf drastische |
| kann das | Problem | der Wasserknappheit |
| können das | Problem | aber nicht |
| wo die | Probleme | liegen , |
| oder wenig | Probleme | mit Sprachen |
| der die | Probleme | in Bosnien |
| - und | Probleme | - der |
| EURAC education | Probleme | werden gerne |
| nicht die | Probleme | , sondern |
| Vorteile und | Probleme | einer dreisprachigen |
| die täglichen | Probleme | der christlichen |
| möchten sie | Probleme | und mögliche |
| Sitzungen , | Probleme | jeweils eines |
| in die | Probleme | des Reiseziels |
| und rechtlicher | Probleme | . Um |
| besonders verfassungsrechtliche | Probleme | gelöst werden |
| noch viele | Probleme | zu lösen |
| für vergleichbare | Probleme | gesucht werden |
| Diskussion gemeinsamer | Probleme | geben unsere |
| und über | Probleme | und Perspektiven |
| Lösung aktueller | Probleme | zu unterstützen |
| stehen die | Probleme | , die |
| Forscher hochaktuelle | Probleme | unserer Zeit |
| bringen versteckte | Probleme | im Unternehmen |
| sich von | Problemen | gedanklich zu |
| mit rechtlichen | Problemen | grenzüberschreitender Zusammenarbeit |
| , inwieweit | Transportprobleme | mit Hilfe |
| oder globale | Umweltprobleme | . Die |
| Alpenregionen gehen | Verkehrsproblem | gemeinsam an |
| Agenda der | Welt-Probleme | . Und |
Uses: Structured Parallel Coordinates
Extending the familiar
Uses: xLDD
Connecting with the data
Uses: xLDD
Flexible components
Uses: xLDD
Goethe on seeing
-
Man erblickt nur, was man schon weiß und versteht.
You glimpse only what you already know and understand.
-
Was man weiß, sieht man erst!*
You see first what you know!
Was man weiß, sieht man erst!
Denn wie derjenige, der ein kurzes Gesicht hat, einen Gegenstand besser sieht, von dem er sich wieder entfernt,
als einen, dem er sich erst nähert, weil ihm das geistige Gesicht nunmehr zu Hülfe kommt,
so liegt eigentlich in der Kenntnis die Vollendung des Anschauens.
Sources:
Kanzler F. v. Müller, Unterhaltungen mit Goethe, 24, April 1819, cited in Lexikon Goethe-Zitate
Einleitung in die Propyläen
Perception and Visualization
-
Visual perception = pattern recognition
-
"Preattentive" / Tunable features
-
Attention
Sources: VHS Tübingen,
photo by L. Lee McIntyre
Testing in new contexts
Uses: ProD
Which visualization for task, user?
Uses: ProD
Dataset genres


Sources: on archive.org, on archive.org
* Difference between genre and data genre:
data genre is a collection of instances of a genre, with additional properties of the collection
e.g.
an individual letter is an instance of the correspondence genre
but not of the correspondence-exhange data genre
* cf. Discursis workshop/paper, similarities and differences between conversations and correspondence
Continuity visualization 1
Continuity visualizations 2 and 3
* Adjacency High Frequency: EBB uses the high frequency words more than RB does, except for "heart".
* Adjacency High Frequency: Connection between word frequency and co-occurrence freq (box sizes)
* Adjacency Lower frequency: in this range EBB uses her higher frequeny words than RB does those words
* Adjacency Lower frequency: in this range no connection between overall word frequency (or for EBB or RBB) and co-occurrence freq
* Hopefully, they are asking questions: What about X? Could you show Y? Why not Z?
Visualizations put ideas into our heads!
←
→
/
#